大小端字节序问题让人十分头疼,死记硬背并不能加深对大小端字节序的理解。但是从数据可视化的角度,就能理解大小端字节序,让人豁然开朗。
问题来源
字节序,又称端序或尾序(英语中用单词:Endianness 表示),在计算机领域中,指电脑内存中或在数字通信链路中,占用多个字节的数据的字节排列顺序。
字节的排列方式有两个通用规则:
- 大端序(Big-Endian)将数据的低位字节存放在内存的高位地址,高位字节存放在低位地址。这种排列方式与数据用字节表示时的书写顺序一致,符合人类的阅读习惯。
- 小端序(Little-Endian),将一个多位数的低位放在较小的地址处,高位放在较大的地址处,则称小端序。小端序与人类的阅读习惯相反,但更符合计算机读取内存的方式,因为CPU读取内存中的数据时,是从低地址向高地址方向进行读取的。
通常在计算机内部,小端序被广泛应用于现代 CPU 内部存储数据;而在其他场景,比如网络传输和文件存储则使用大端序。
从网络数据可视化看大端序
一般网络字节序为大端字节序,因为UDP/TCP/IP协议规定:把接收到的第一个字节当作高位字节看待,网络数据解析时先收到的数据存放于低地址,否则内存的访问将是不连续的。 所以,大端字节序 = 网络字节序 = 高位放低地址。
对于整形数0x11223344,采用网络传输时,从wireshark中抓到的消息包,如下所示:
1 | 0 1 2 3 4 5 6 7 8 9 A B C D E F |
从wireshark的数据可视化角度可知,网络通信采用大端序,低地址存储高位字节,高地址存储低位字节,符合人类阅读习惯。
从内存分布可视化看小端序
操作系统内存布局
Windows在默认情况下会将高地址的2GB空间分配给内核(也可以配置为1GB),而Linux默认情况下会将高地址的1GB空间分配给内核。也就是说,应用程序只能使用剩下的2GB或3GB的地址空间,称为用户空间(User Space)。
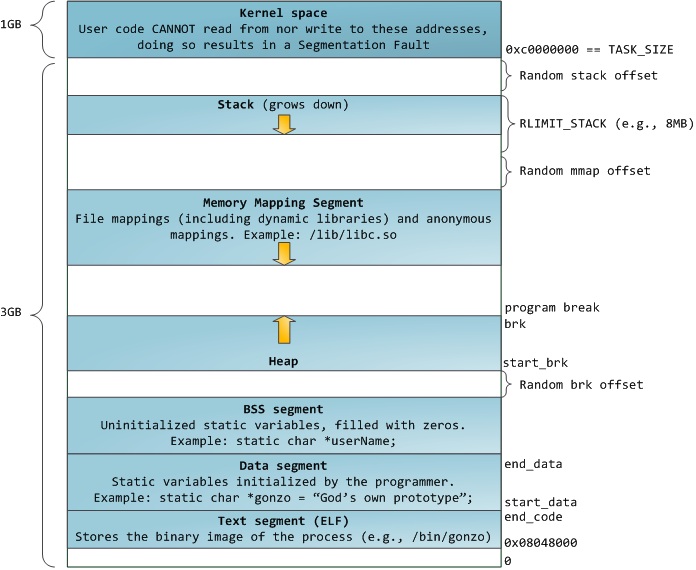
应用程序性用户空间布局
- 堆(heap)的增长方向是向上增长,即低地址向高地址增长。
- 栈(stack)的增长方向是向下增长,即高地址向低地址增长。

应用程序中定义的变量通常在栈区存储,而栈(stack)的增长方向是向下增长,即高地址向低地址增长。因此,从如下可视化角度查看数据是合理的。
1 | F E D C B A 9 8 7 6 5 4 3 2 1 0 |
参考链接
- 什么是大端序和小端序,为什么要有字节序?,by Kevin Yan.
- Windows下C语言程序的内存布局,by 朴素贝叶斯.
- 一文弄懂大小端字节序/网络字节序,by Linux加油站.
- 为什么堆和栈的增长方向相反?,by 嵌入式ARM.